Last IO update¶
Introduction¶
This write-up covers the series of events in case of a compute client crash and the steps taken to maintain consistent data.
When a compute client crashes, a write IO sent to all storage nodes may complete on some but not on others — let’s say node X. Either the write failed, or the compute client was unable to send it over the network before the crash. This means a map_add message should be sent to all other nodes to inform them that the chunk is dirty for node X. This map_add is normally sent by the compute client when it notices the IO error, but since the compute client is dead, the message is not sent. The result is data written to some nodes but not node X, with no record that the chunk is dirty on node X — a potential data inconsistency.
The way this is solved is by tracking the last queue_depth number of IOs on all storage nodes.
The last IO update can be driven by a manual sysfs trigger enable or the pool recovery mechanism. On recovery, it runs automatically as part of rmr_clt_pool_try_enable(), which the RMR client invokes whenever a session reconnects (see Client Session States). When the conditions for last IO update are met, try_enable performs it before transitioning sessions back to NORMAL.
Preparations and setup¶
At any point in time, the RMR client pool will not trigger more than queue_depth IOs. It controls this by allocating queue_depth IO units and blocking allocation when all are in use. When an IO unit is freed on completion of an IO, the processes waiting for a new IO unit are woken up. A client of the RMR pool (brmr) must allocate an IO unit to submit an IO to the RMR client. Every IO unit is assigned a number (mem_id) from 0 to queue_depth - 1. This is passed to the storage node through the rmr_req and used when a write completes (described next).
On the storage node, the RMR pool has an array of length queue_depth. When an IO completes, the mem_id from the rmr_req is used as an index into this array, and the chunk ID to which this IO was performed is stored at that index. This is done only for write IOs that have succeeded. The result is a record of the last queue_depth writes performed by a storage node at any point in time.
After a compute client crash, the compute client is revived and reconnects to each storage node. As each session reconnects it transitions to RECONNECTING state, and rmr_clt_pool_try_enable() is called. try_enable decides which recovery path applies:
Case 1: At least one session is already NORMAL. Its map is spread to the other sessions, and they are transitioned to NORMAL. No last IO update is needed.
Case 2: Exactly one RECONNECTING session is marked
was_last_authoritative(it was the last NORMAL session before the pool went fully down). It is enabled directly, and its map is spread to the rest. No last IO update is needed.Case 3/4: Every member listed in
pool_mdis present and in RECONNECTING state. The last IO update path runs.
Last IO update trigger¶
When a last IO update starts, the client should select the most up-to-date map first. It reads the map version from every storage node and picks the one holding the highest version. That node’s map is spread to all other nodes via rmr_clt_spread_map() so every node enters the next step from the same map view. This is important because a node that was down before the crash may hold a stale map; without this step, its last_io entries could be applied on top of stale dirty information and chunks already known to be dirty elsewhere could be silently overwritten.
Once every node holds the latest map, the client sends RMR_CMD_LAST_IO_TO_MAP to each connected storage node. On receiving this command, each node converts its last IO entries into dirty entries for every other node, skipping any chunk already marked dirty for itself. More thoroughly,
on the server side:
A storage node (let’s say X) is chosen and is instructed to convert its saved last IOs (the array) to dirty chunks for all other storage nodes except itself. We cannot know which of the last IOs completed on all storage nodes and which may have completed on only one, so we treat all of them as dirty for all other nodes. We do not mark the chunk as dirty for node X itself because the presence of this chunk ID in its
last_ioarray confirms that the write succeeded for it. Once this is done, a map update is performed, sending the map from node X to all other storage nodes.The above process is repeated for all other storage nodes one by one, translating the
last_ioknowledge into dirty chunks across all storage nodes.The final piece of this algorithm: when a storage node encounters a chunk ID in the
last_ioarray that is already dirty for itself, it skips that entry and keeps it marked dirty for itself. This knowledge that the chunk is dirty for itself may have come from alast_ioupdate by another storage node. If we were to also mark it as dirty for others, we could end up with the chunk marked dirty for all storage nodes even in the case where the last IO was successfully written to all of them.This creates an implicit ordering: the node chosen first to receive
RMR_CMD_LAST_IO_TO_MAP— call it A — is treated as holding the latest data for the chunks in its last IO array. If the same chunk appears in the last IO arrays of other nodes (B and C), those entries are skipped, since A has already marked that chunk dirty for B and C and distributed its map to them.
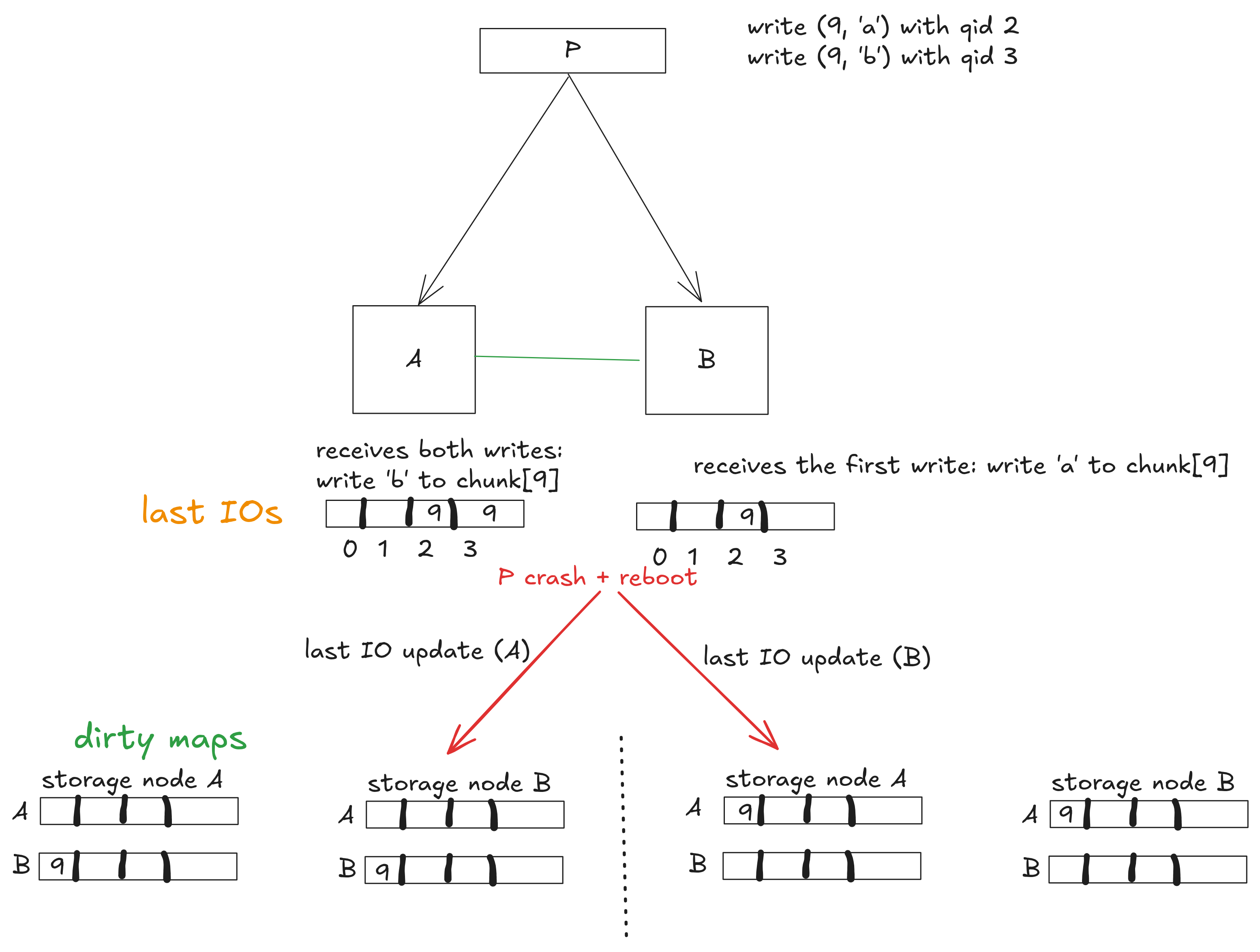
The diagram below walks through the algorithm on a two-node pool. Compute client P issues two writes to chunk 9 ('a' with qid 2, then 'b' with qid 3); A receives both, B receives only the first, and then P crashes. The resulting dirty maps differ depending on which node runs the last IO update first — if A goes first, chunk 9 ends up dirty for B (so B will be resynced from A’s 'b'); if B goes first, chunk 9 ends up dirty for A (so A will be resynced from B’s 'a'). Either way, both nodes converge to the same value regardless of the chosen ordering. This is acceptable because P crashed before it could acknowledge the second write with 'b'. In this case, the block layer doesn’t guarantee that the subsequent read will return 'a' or 'b', only that it will return a consistent value.
After these steps complete, try_enable transitions all RECONNECTING sessions to NORMAL. IOs can now run safely.